
What is denormalization?
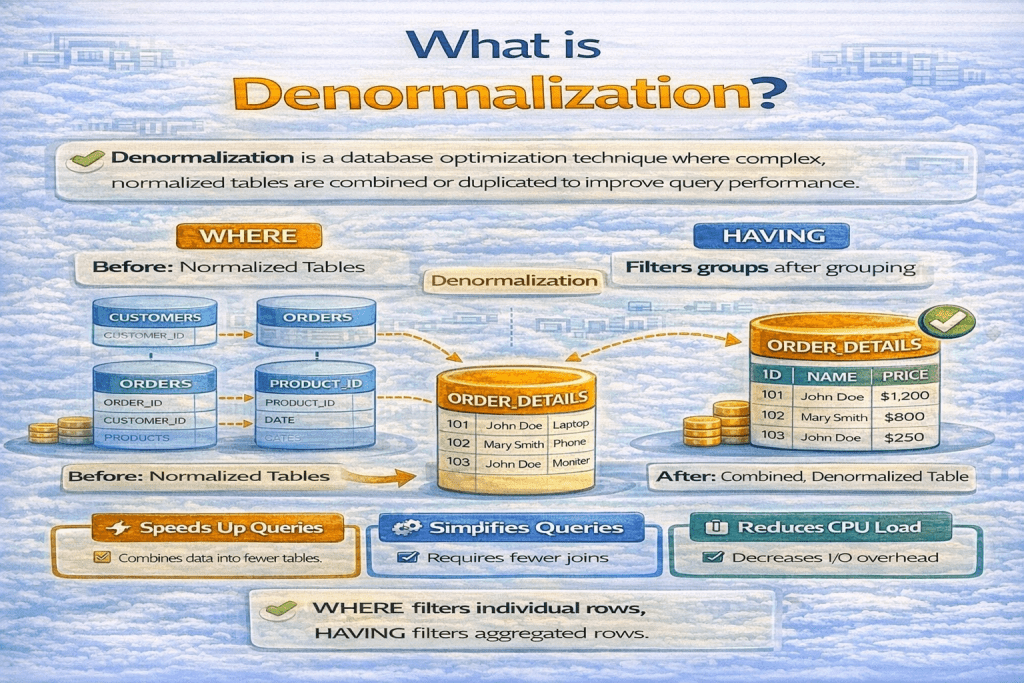
Denormalization is the process of intentionally introducing redundancy into a database that has been normalized. In simpler terms, it’s the opposite of normalization. While normalization aims to reduce data duplication and improve data integrity, denormalization sometimes adds redundancy to improve performance, usually for faster read queries.
Here’s a detailed explanation:
Key Points:
- Purpose:
- Improve query performance (especially read-heavy operations).
- Reduce the number of
JOINoperations needed to fetch data.
- When to Use:
- In data warehousing and reporting systems where fast retrieval is more important than strict storage efficiency.
- When complex joins on normalized tables slow down queries.
- How It’s Done:
- Adding redundant columns: e.g., storing
customer_namein anorderstable even though it exists in thecustomerstable. - Merging tables: Combining two normalized tables into one for faster access.
- Precomputing values: Storing computed aggregates like
total_salesin a table instead of calculating each time.
- Adding redundant columns: e.g., storing
- Pros:
- Faster read/query performance.
- Reduced complexity of queries.
- Cons:
- Increased storage.
- Higher risk of data inconsistency.
- More effort required to maintain data integrity (updates need to be done in multiple places).
Example:
Suppose we have a normalized database with two tables:
Customers:
| customer_id | name | city |
|---|---|---|
| 1 | Alice | Delhi |
| 2 | Bob | Mumbai |
Orders:
| order_id | customer_id | amount |
|---|---|---|
| 101 | 1 | 500 |
| 102 | 2 | 300 |
If we denormalize, we might store customer_name directly in Orders:
Orders (Denormalized):
| order_id | customer_id | customer_name | amount |
|---|---|---|---|
| 101 | 1 | Alice | 500 |
| 102 | 2 | Bob | 300 |
This way, querying customer_name with orders is faster because we don’t need a JOIN.
No comments yet! You be the first to comment.